OpenAI recently introduced SWE-Lancer, a benchmark that tests how well today’s most advanced AI models can handle real-world software engineering tasks. Even though they just tweeted about it 19 hours ago, this paper is already the top paper on AIModels.fyi in the agents category and growing fast.
Their paper presents a benchmark that evaluates AI language models on 1,488 actual freelance software engineering tasks from Upwork, collectively worth $1 million in payouts. These tasks were sourced from the open-source Expensify repository.
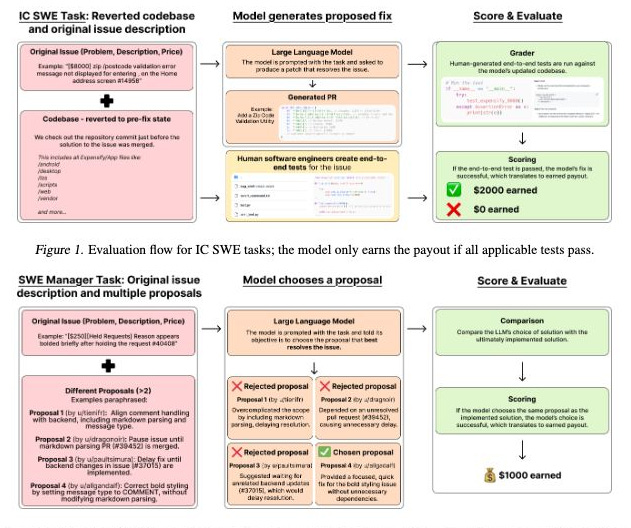
The benchmark includes two distinct types of tasks. First are Individual Contributor (IC) tasks, which comprise 764 assignments worth $414,775, requiring models to fix bugs or implement features by writing code. Second are Management tasks, consisting of 724 assignments worth $585,225, where models must select the best implementation proposal from multiple options.
What makes this benchmark particularly meaningful is that it measures success in real economic terms – when a model correctly implements a $16,000 feature, it’s credited with earning that amount.
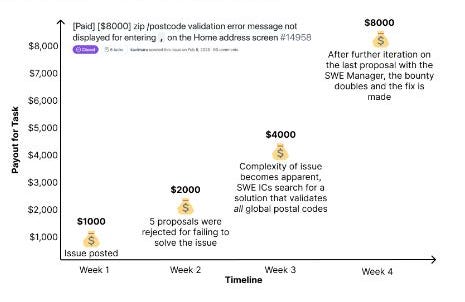
The results reveal some crazy impressive stats around AI’s ability to handle complex software engineering work.