As 2019 draws to a close and we step into the 2020s, we thought we’d take a look
back at the year and all we’ve accomplished. And we realized we had so much that
we could give you a month-by-month rundown of everything that happened.
We’re also very happy to see our team grow this year, with four new
members working under the Explosion umbrella:
Sofie Van Landeghem, Adriane Boyd, Walter Henry
and Sebastián Ramírez.

- 📻 Jan 15: The year started out with us as guests on the
NLP Highlights podcast,
hosted by Matt Gardner and Waleed Ammar of Allen AI. In the interview, Matt
and Ines talked about Prodigy, where training corpora come
from and the challenges of annotating data for an NLP system – with some ideas
about how to make it easier. - 📺 Jan 16: Ines followed that up with an appearance on
German documentary “Frag deinen Kühlschrank”
(literally “ask your refrigerator”) for Bayerischer Rundfunk on German TV
about AI technologies. It also included a small glimpse of spaCy, Prodigy and
our day-to-day work on GitHub. - 🎤 Jan 28: Ines then joined the great lineup of
Applied Machine Learning Days in Lausanne,
Switzerland. Ines’ talk in the language track,
“Practical Transfer Learning for NLP with spaCy and Prodigy”,
focused on the increasing trend of initializing models with information from
large raw-text corpora, and how you can use this type of technique in spaCy
and Prodigy.

- 💻 Feb 1: February kicked off with this neat little thing we built: a
wrapper for the new Stanford NLP library!
Now their state-of-the-art Universal Dependencies models can be directly used
in your spaCy pipeline. - 💻 Feb 1: That same day, we merged
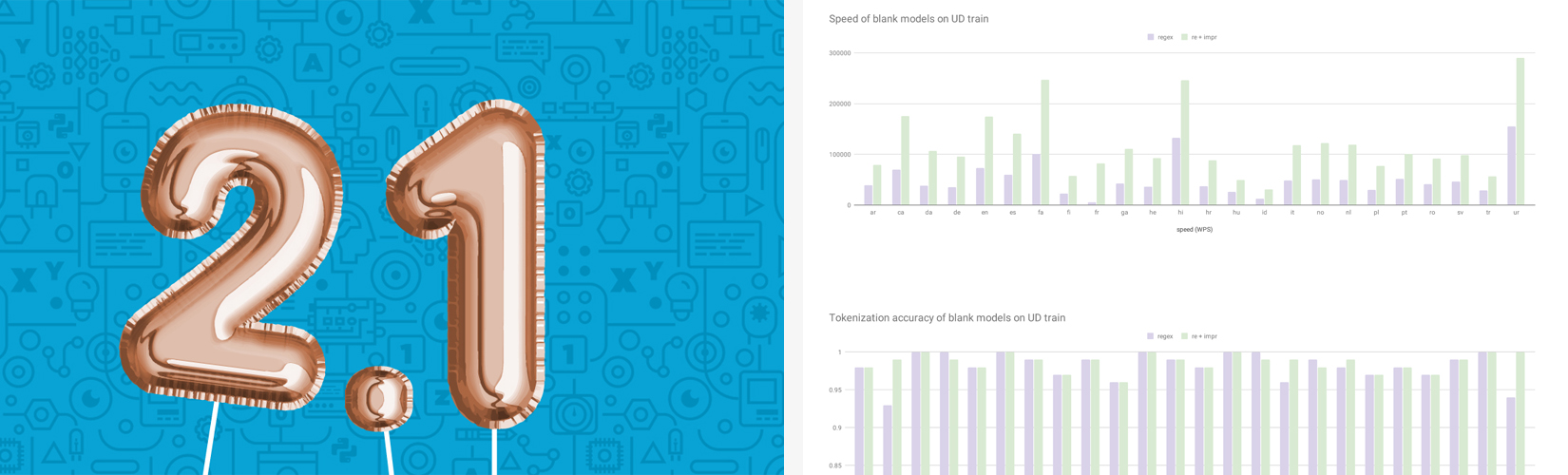
this awesome PR by
Sofie Van Landeghem, increasing tokenization
speed by 2-3 times across languages at the same accuracy by refactoring the
regular expression and replacing regex with re. This is a bit of a double
landmark as it marks the beginning of our amazing working relationship with
Sofie, who has since joined the spaCy core team full time. - 📺 Feb 6: This month we also released a little
FAQ video, which was really fun
to make. In it, Ines gives tips and tricks for NLP annotation and training
based on common advice we’ve been giving to Prodigy and spaCy users. Got a
question? Check out the video and see if we’ve already got your answer. - ✨ Feb 18: Finally in February, Prodigy v1.7.0 was
released – our first major upgrade to Prodigy for 2019. This update made it
easy to set up named multi-user sessions in a single instance and use some of
the multi-user features we’ve developed for the upcoming Prodigy Teams. It
also introduced a new setting for instant submissions and support for custom
CSS and JavaScript across all interfaces.
- 📻 Mar 9: Ever been curious about how Explosion makes its money? Rather
than talk programming, Ines started off March by sitting down and discussing
building a software business on
Michael Kennedy’s TalkPython podcast.
This was a fun way for us to tell another side of the Explosion story. - 💻 Mar 18: March also saw spaCy v2.1 released – the
first big spaCy update of the year! The update fixed outstanding bugs on the
tracker, gave the docs a huge makeover, improved both speed and accuracy, made
installation significantly easier and faster, and added some exciting new
features, like ULMFit/BERT/ELMo-style language model pretraining. - ✨ Mar 20: A few days later, we upgraded Prodigy to
v1.8 to support spaCy v2.1. There was also now support for pretraining, new
recipes for reviewing annotations and resolving conflicts, multiple-choice
text classification, easy dataset merging and more. - 🎤 Mar 25: Towards the end of the month, Ines had the honor to be a guest
at WiDS (Women in Data Science) Poznań, where
she talked practical transfer learning for NLP.
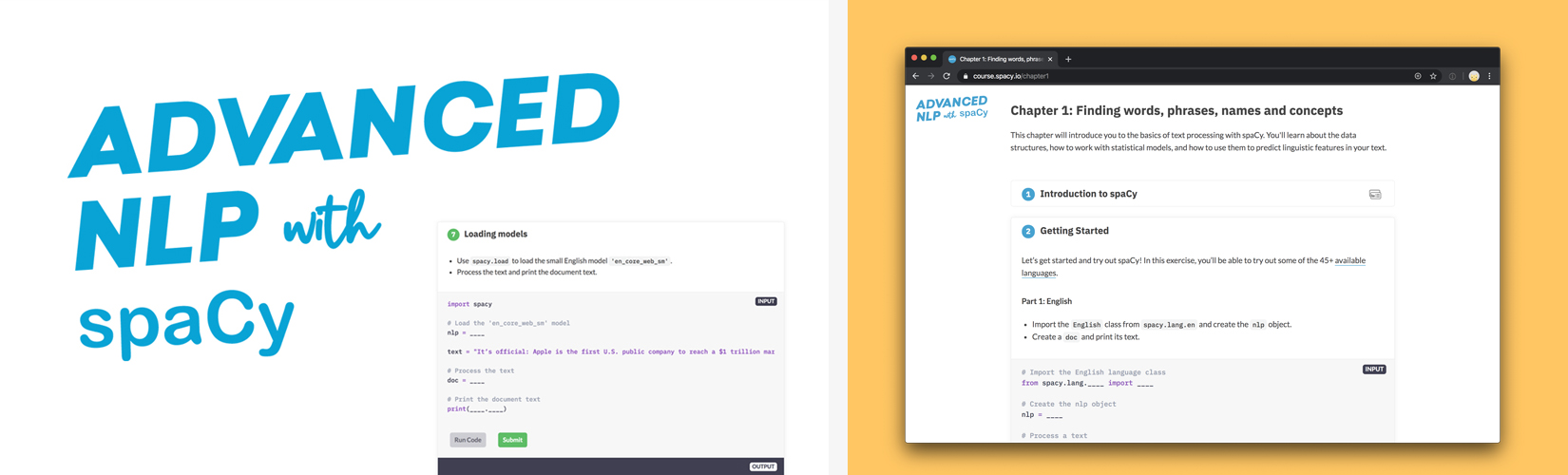
- 🏫 Apr 17: In April, we released our popular free
Advanced NLP with spaCy course. Ines built the
interactive app to be used by anyone wanting to learn spaCy… and people had
a lot of fun with it – including Explosion’s “non-tech” hire, Walter.
-
📻 May 7: In May, Ines got the chance to sit down with Sam Charrington for
the
TWiML Podcast.
They got to talking about spaCy, spaCy’s focus on industrial use cases and
open source in general. -
💻 May 12: May also featured another jump up for spaCy when we released
v.2.1.4. which included improved training commands alongside the usual bug
fixes.
- 📻 Jun 3: While we were busy preparing some things for early July, we did
take time with Kunal Jain on
Data Hack Radio by Analytics Vidhya
to talk the early days of spaCy, what’s guided the library’s development and
how machine learning is kind of like web development. - 🤝 Jun 24: Sofie Van Landeghem joined the Explosion team! Sofie
has been involved with machine learning and NLP as an engineer for 12 years.
This year her work collided with Explosion (or more specifically spaCy) and we
started working together in February. She is currently one of the core
developers of spaCy. Sofie’s main project has been spaCy’s
new entity linker component.
More recently, she’s also been working on the
Hugging Face Neuralcoref
component, which we hope to have merged into the core library early next year.

- 🎉 Jul 4-6: And then there was: spaCy IRL,
our first big conference, which took place in Berlin at the historic
Heimathafen Neukölln. We had already decided at the end of 2018 that we wanted
to do this and after seven months of planning and hard work, we couldn’t have
been happier with the result. The main event was sold out with 200 attendees
and we had 13 speakers including
Yoav Goldberg and
Sebastian Ruder as keynotes.
This was accompanied by trainings attended by 70 people – a second was added
to the original because of the demand. - 📻 Jul 18: After a brief rest following spaCy IRL, Ines took a minute to
appear on the
Python Bytes
podcast with Michael Kennedy and Brian Okken. Among other things, Ines
discussed fast.ai’s new course on Natural Language
Processing and using Polyaxon for model training and
experiment management. - 📰 Jul 29: Then it was really nice to see Ines featured as the
PyDev of the Week on the Mouse vs. Python blog
at the end of the month. Check out the interview and see what Ines had to say
about her early days with programming, how she got into Python and some
current projects (at the time).

- 💻 Aug 2: August started off with an exciting release as we introduced
spacy-transformers. With this new library, you
can now use huge transformer models like BERT, GPT-2 and XLNet in spaCy, via a
new interface library we developed that connects spaCy to
Hugging Face’s awesome implementations. - 📺 Aug 21: Our official spaCy learning materials canon grew at the end of
August to include a new video series:
“Intro to NLP with spaCy” hosted by Vincent Warmerdam.
We first met Vincent in person at a conference, and his funny, outgoing
personality was a perfect fit for a video series. - 📰 Aug 29: Ahead of her appearance at the Zündfunk Netzkongress in Munich
in November, Ines appeared in an
article on BR.de
(German) discussing the pitfalls of placing too much hope in artificial
intelligence.

- 🤝 Sep 2: Walter Henry joined the Explosion team. Walter has
been a writer and journalist living in Berlin for the past 10 years mostly
working in cultural journalism. Through his longstanding working relationship
with Ines, he began to freelance for Explosion in small capacities in 2018.
This past summer he came on board to help with the event management for our
very successful spaCy IRL. In September he
officially came on as Explosion’s first non-tech hire and assists the team in
a variety of ways. - 💻 Sep 4:
spacy-transformerskept
getting better as we released v0.4.0, which added support for Hugging Face’s
DistilBERT, a pre-packaged DistilBERT model and more. - 🤝 Sep 15: Adriane Boyd makes up the second spaCy developer team
hire in 2019. Adriane is a computational linguist who has been engaged in
research since 2005, completing her PhD in 2012. She started participating in
the spaCy community in Spring this year, and we met up with her at the spaCy
IRL conference. After a few freelance projects, we were thrilled to have
Adriane join the team full-time. Adriane started out working on our internal
systems for datasets and evaluation, and has gone on to make tons of
improvements across the library. - 💘 Sep 19: As a thank you to our community, we started sending out another
round of stickers
(the first was in 2017) – this time going out to over 1100 people by the end
of the year. - 📺 Sep 24: Data science instructor Vincent returned for
“Intro to NLP with spaCy #2”.
In this episode he built a rule-based matcher to bootstrap an NER pipeline.

- 🤝 Oct 1: Sebastián Ramírez joined the Explosion team! Many of
you might recognize Sebastián’s name as the author of
FastAPI, the new Python library for
modern REST APIs that’s quickly becoming the industry standard and is known
for its incredible technical documentation. When we finally met Sebastián we
knew it was a perfect match and he moved from Colombia to Berlin to join the
team here. He’s working on the upcoming Prodigy Teams and a lot of other cool
stuff. - 💻 Oct 2: spaCy got a big upgrade in October with the
release of v2.2! Among the new features are core models
for Norwegian and Lithuanian, Dutch NER with more labels, it’s 5-10 times
smaller on disk and 10 times faster in phrase matching, it efficiently
serializes collections of Doc objects and there’s CLI for textcat training and
data debugging. - 🏆 Oct 10: This month we were also proud to
accept the META Seal of Recognition
at META-FORUM 2019 in
Brussels, along with Mozilla. The META-FORUM is an international conference
series backed by the European Union on powerful and innovative Language
Technologies for a multilingual information society. - 🎤 Oct 12-15: Following that right up, Ines and Matt were delighted to
take part in PyCon India in Chennai. Matt
talked about how to use huge
transformer models such BERT in spaCy throughspacy-transformers. Ines was
proud to present the
keynote,
playfully titled “Let Them Write Code” – you can
watch whole talk here. - 💻 Oct 31: spaCy gets one last update before the month is out in v2.2.2.
The new features
this time around include multiprocessing in nlp.pipe, a simpler GPU install
and setup, base support for Luxembourgish and model fixes, as well as
forwards-compatible support for future APIs.
- 📰 Nov 1: In November, Ines sat down with German magazine
Kulturnews for an interview. - 🎤 Nov 8: Coinciding with her trip to Munich to speak at Zündfunk, Ines
took time out to speak at the
Hacking Machine Learning Meetup
aboutspacy-transformers. - 🎤 Nov 9: The main reason for the trip to Munich though was the fun and
thoroughly informative
Zündfunk Netzkongress at the Münchner
Volkstheater. Ines’ talk
“Künstliche Intelligenz: Beyond the Hype”
(German) touched on the dangers of unconditional belief in technology, as well
as romanticizing the past. - 📺 Nov 9: Ines also did a fun little interview for German TV channel
Bayerische Rundfunk about her talk at Zündfunk. You can
watch it here
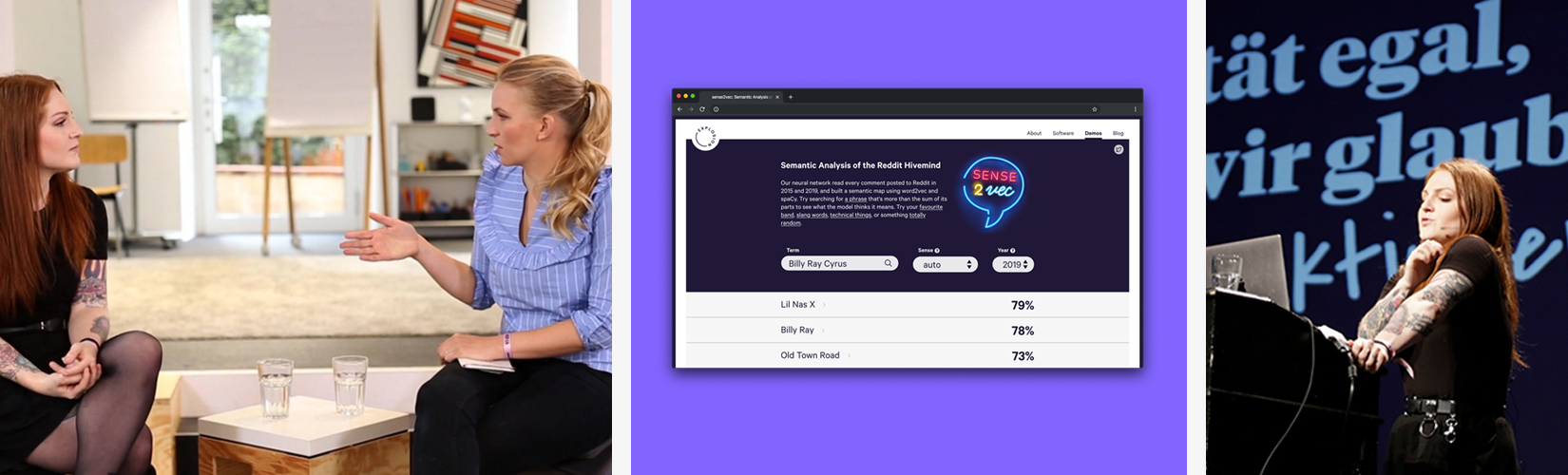
(in German). - 💻 Nov 22: This milestone was also one of the most fun:
sense2vec reloaded! We updated the library, models
and demo to compare 2015 and 2019 using contextually-keyed word vectors
trained on billions of words from Reddit comments. Basically, it’s an
at-a-glance look at how (quickly) language has changed over the past four
years. Even your non-NLP friends can have fun with this. Go ahead,
try it out and enter “Billy Ray Cyrus”, “AOC” or whatever
you’d like. - 💻 Nov 22: Towards the end of the month we started
open-sourcing some of our datasets and NLP example projects.
The projects include 1000 annotated examples each, training/evaluation
scripts, results, data visualizers and some powerful tok2vec weights trained
on Reddit to initialize models. - 📰 Nov 28: Ending November,
Ines was featured on SourceSort,
a platform interviewing open source developers, about complementing the 15k+
star open-source project spaCy with
commercial developer tools, namely Prodigy. There’s also a
bit of spaCy history in there as well.
-
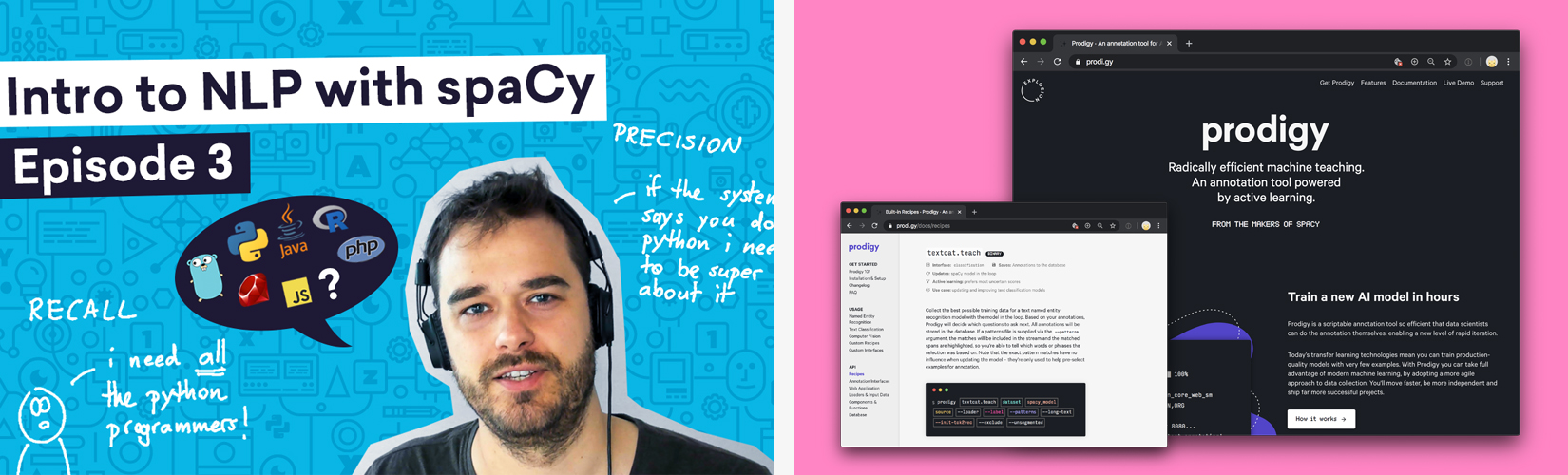
📺 Dec 7: Vincent returned again in early December for
“Intro to NLP with spaCy #3”.
In this episode he explained how to transition a rule-based prototype towards
an NER model to achieve faster results and a baseline for machine learning
experiments. -
🖊 Dec 9: Ines’
key thoughts on trends in AI from 2019 and looking into 2020.
If you want to read a few key thoughts on trends in AI from 2019 and a
lookahead into 2020, take a look… Ines summed it up here in a short and
informative post. -
📻 Dec 9: In a final podcast appearance for the year, Matt and Ines spoke
to Daniel Whitenack and Chris Benson on
Practical AI to talk spaCy, its
history and of course some thoughts on the latest trends in NLP. -
✨ Dec 18: And last but not least, we end the year with our biggest
release so far: Prodigy v1.9. This release includes a new
site and tons of new docs, new training and data conversion
recipes, a
“blocks” UI for combining interfaces,
a UI for
free-form text input and
lots, lots more!
With the community and the team continuing to grow, we look forward to making 2020 even better. Thanks for all your support!