Developer productivity has been central to our design of
spaCy, both in smaller decisions and some of the bigger
architectural questions. We believe in embracing the complexities of machine
learning, not hiding it away under leaky abstractions, while also maintaining
the developer experience. Read on to learn some of the design patterns within
the library, how we’ve implemented them, and most importantly, why.
Within spaCy, we work on prioritizing how to:
- balance ease-of-use vs. customizability
- help prevent bugs, and debug them when they happen
- improve readability
- provide tooling for complex and adaptable software projects
In this blog post, we’ll be taking a deeper behind-the-scenes look at “how” and
“why” we decided to design the newer versions of our library. If you’re more
interested in the “what”, you can check out
this blog post. This post is based on a
video I made when spaCy v3 was released, you can
watch it here!
In October 2019, I was invited to Chennai to give a
keynote at PyCon India. The title of my talk was
“Let Them Write Code,” and I explained why good developer tools need to be
programmable, instead of trying to anticipate everything the user might want to
do and only offering leaky abstractions. In the talk, I also showed some
practical ideas for making developer tools customizable without compromising the
developer experience. Many of those ideas were directly inspired by what we were
working on for spaCy v3 and its machine learning
library Thinc at the time.
When spaCy was first released in 2015, the way people did NLP was quite
different from the way people are doing NLP today. This goes beyond embeddings,
transformers, and transfer learning – it’s not just a question of technical
advancements within the community. Today, far more teams have at least one
person with quite a lot of experience in machine learning, and organizations
have learned more about what types of projects are likely to get results. Deep
learning, by its nature, also gets you involved at a different level of
abstraction: once you get into the details, you may want to add layers to a
model or access the raw outputs. These are workflows that we want to support in
spaCy. But at the same time, we want to stay true to the library’s vision of
providing useful pre-configured building blocks you can use right away. We want
to maintain the library’s ease of use – but to do that, we need to get the
architecture right. We can’t sweep the complexity under the rug.

The design
Machine learning is complex. If we want to provide a better developer
experience, we need to face this complexity head-on and not just cover it up
with a bunch of abstractions and hide it away. spaCy provides a powerful
developer experience for customizing almost every part of the pipeline and
neural network models, including the ability to plug in any custom models
implemented in any framework. At the same time, we want to make it easy to get
started and provide reasonable defaults so new users can get going, be
productive, and train models as quickly as possible.
We also want to ensure there’s typically only one way to do things.
Previously, training models on the command line was more convenient but less
extensible, and writing your own training scripts was more flexible but also
more complicated – especially when it comes to getting the little details and
hyperparameters right. spaCy now focuses on one workflow for training models:
using spacy train on the command line, with
a single configuration file defining all settings, hyperparameters, model
implementations, pipeline settings, components, component models, and
initialization.
python -m spacy train config.cfg --output ./output --paths.train ./train --paths.dev ./dev
The config is the single source of truth and it also includes all settings and
records all defaults. Even if you’re training with the default configuration and
aren’t planning on customizing anything, your config will still include all
settings. Given the same config, you should always be able to reproduce the same
results.
The config is parsed as a dictionary and can include nested sections, indicated
using the dot notation. For example, training.optimizer.
[training]
dropout = 0.1
accumulate_gradient = 1
[training.optimizer]
@optimizers = "Adam.v1"
[training.optimizers.learn_rate]
@schedules = "warmup_linear.v1"
warmup_steps = 250
total_steps = 20000
initial_rate = ${vars.learn_rate}
[vars]
learn_rate = 0.001
Under the hood, it’s a variation of Python’s built-in
configparser, which is
also used to parse things like the setup.cfg. But we took the config syntax
one step further and also allowed any JSON-serializable values that are parsed
when the config is loaded, as well as a more flexible variable interpolation
that lets you reference config values in nested and whole sections.
What makes the config special is that it doesn’t only support JSON-serializable
values but also supports references to functions used to create an object – like
a model architecture, an optimizer, a corpus reader, and so on. You don’t want
to fall into the trap of programming via a config file and having the config
define logic – Python is perfectly fine for that. So instead of defining the
actual logic, the @-syntax lets you refer to a function that creates an object.
For example, @optimizers lets you define the string name of a function in the
optimizers registry. All other settings in that block will be passed to the
function as arguments.
🍬 Confection: The sweetest config system for Python
We’ve recently released the configuration system on its own as
confection, a light-weight package
independent of Thinc and spaCy that’s easy to include in any Python project.
When the config is resolved, the functions are called to create the objects like
the optimizer. The config is resolved bottom-up, so we always start at the
outermost leaves and work up the tree. This means we’re able to flexibly
compose functions and pass the object returned by one function into another as
an argument. Let’s take the optimizer and learning rate as an example. There are
different strategies for how to vary the learning rate, and it’s often something
you want to customize. A more classic approach would be to initialize our
optimizer with a bunch of settings, including how to create the learning rate
schedule. That works, but you’ll be hitting a roadblock pretty quickly: there
are lots of arguments, many of which only make sense in certain combinations,
and it becomes difficult to swap in a fully custom strategy, like something new
you just read about in a paper and want to try out.

The more composable solution is to pass in the learning rate schedule itself as
a generator that yields the sequence of learning rates you want. On the config
level, this means that the learn_rate argument of the optimizer is a
sub-section that references a function. As the config is resolved bottom-up, the
learning rate function is called first, and its return value is passed in when
the optimizer is created.
The same applies to
pipeline components and
model architectures. Previously, a
pipeline component would create its neural network model, which would be
customizable with a few settings. We call this pattern “top-down configuration,”
and once you begin thinking about it, you’ll probably see it all over the place
and notice the problems it introduces. One is that the topmost object needs to
receive settings and then pass them down to other objects it creates and
functions it calls, which then pass down settings to whatever they call and
create, and so on. One value may have to be passed down in multiple places. As
soon as you miss passing it on, a default may get activated without you
realizing it.
For instance, a pipeline component might have a setting to define the width of
its embeddings table. It then creates a model instance and passes down the
width. The model then creates one or more layers using that number. If you
forget to pass it down to one layer, it might fall back to using its default
width, which might be different. With a top-down configuration, you can easily
end up with mismatched configurations and very subtle and deeply nested bugs
that are difficult to track down.

To avoid this problem, you want to build your trees of objects bottom-up.
You don’t want to pass in settings and have your function create an object with
them – you want to pass in the instance instead. This stops the config from
being passed along. From spaCy v3 onwards, trainable components are typically
initialized with a model instance which is defined in the config. Model
architectures often also take sublayers, created by functions. This means that
the component doesn’t have to be in charge of passing down a bunch of settings.
It also allows components and model architectures to be modular, so if you want
to experiment with a different architecture or embedding strategy, just swap it
out of your config.

Now, you might be looking at this and ask yourself: why on earth are we doing
all of this? We’re writing functions that we’re then assigning string names to,
so we can use those in a separate file. Why not just use the functions directly?
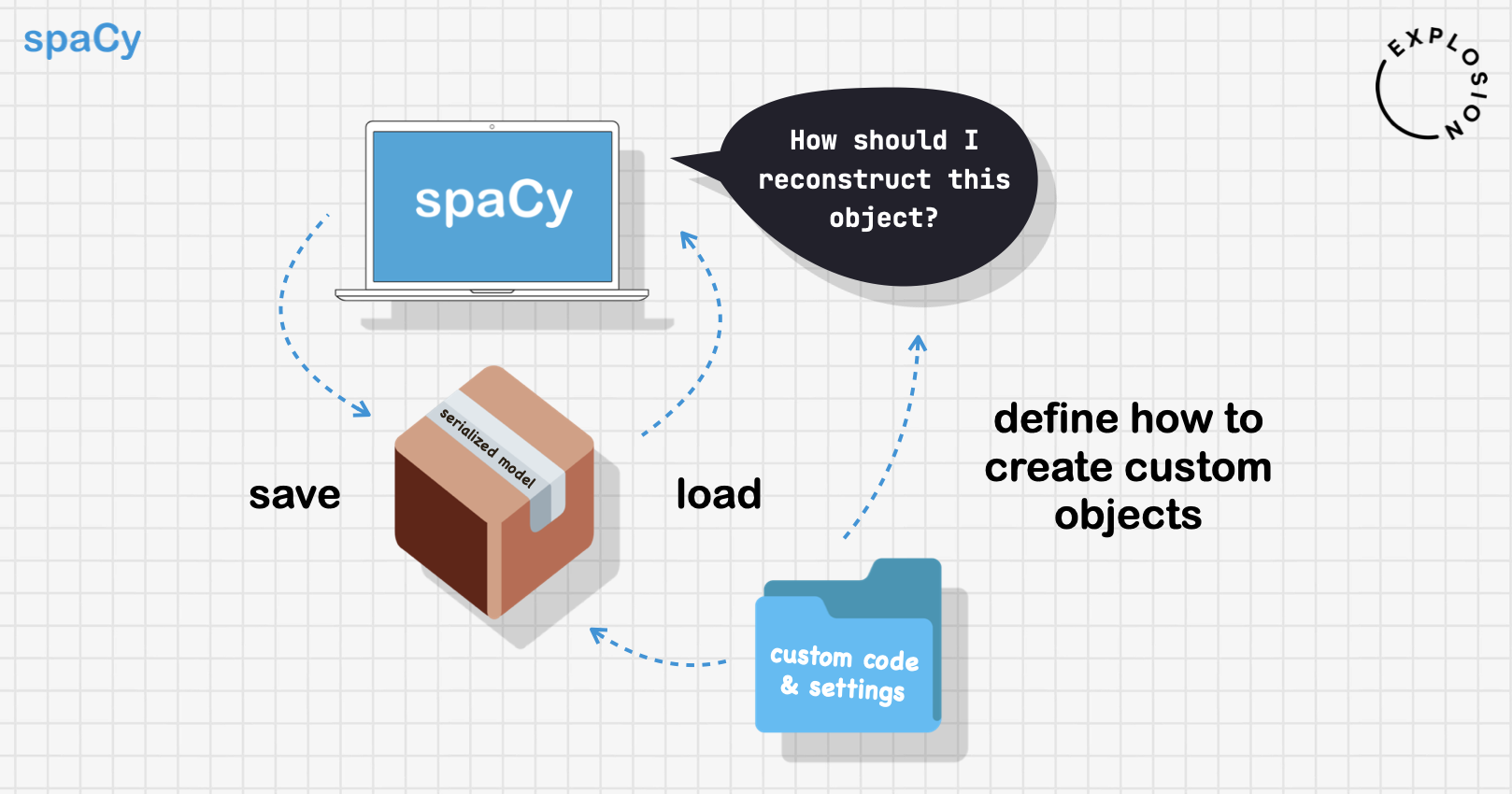
Well, as much as a pipeline needs to be programmable, it also needs to be
serializable. Serialization is the process of converting states – like a
Python object or data structure – into a format that can be stored or
transmitted, and reconstructed later. For example, saving a model you’ve trained
to a directory on a disk, and loading it back later. When you recreate the
object, you want it to be exactly what you saved. In the context of spaCy, this
means that the pipeline should use the same language and tokenizer settings, the
same components with the same settings, model architectures and hyperparameters,
and access to the same binary weights. So when you load back a trained entity
recognizer, spaCy will create the component, configure it and load in the data.
You also want to limit what you save to what’s necessary and use a safe format
like JSON wherever possible, not just pickle the entire object and make the user
execute arbitrary and potentially unsafe code. spaCy’s built-in pipeline
components implement their own serialization methods that take care of saving
and loading the settings and weights. So given a directory and knowing that it’s
an entity recognizer, spaCy will be able to reconstruct the object.
However, this gets trickier when the objects that need to be created are defined
by the user. In spaCy v3, we made pretty much every part of the pipeline and
training process configurable with custom functions: you can plug in your own
model implementation for a pipeline component, tweak the embedding layer of an
existing component model, use a custom optimizer or batch size schedule or swap
out the function that streams in the training data.
A lot of these customizable parts are used in different places across the core
library – like the functions used to create custom pipeline components or the
settings that define how to initialize a blank pipeline. We don’t want to keep
passing those functions around all the time. Instead, we want spaCy to be able
to ask, “Hey, is there a function for a component called relation_extractor?
And do we have a function to create a learning rate schedule called
slanted_triangular“?
We need a central place to store and register our functions: a function
registry. Function registries let you map string names to functions. That’s
it. It’s a simple concept but very powerful: a string name uniquely identifies a
function that creates an object and given a string and the global registry, we
can always recreate it.
REGISTRY = {}
def register(name):
def register_function(func):
REGISTRY[name] = func
return register_function
@register("my_function")
def my_function():
...
The underlying implementation, which we’ve open-sourced as a lightweight mini
library called catalogue, is pretty
straightforward. We keep a global registry, like a dictionary mapping strings to
functions, and use a decorator to add the function it decorates to the registry.
It also supports registering functions via Python entry points, so third-party
packages can expose functions for an existing registry without requiring the
user to import the package.
Now within the library, we can look up any string name in the registry. To
register a custom function, all a user has to do is decorate it with the
registry decorator and assign it a name. This allows users to easily customize
behavior that’s deeply nested in the library or within other functions. And we
can store this information in a safe format, like a JSON-serializable config
file. If the registered functions are available, meaning if the decorator runs,
the library will always know how to create an object.
This is very convenient, but it depends on a simple premise: we need to know and
track how an object was or expects to be created. If all we have is an object,
we’re unable to create it again. This is by the way also the reason we ended up
making one significant change to the pipeline component API and introduced a
decorator to register custom components.
nlp.add_pipe is now only allowed to
take a string name instead of the component function itself.

As we’ve mentioned before, many of the newer features in spaCy are a result of
rethinking the developer experience around inherently complex tasks. We want
to provide workflows that are powerful, extensible but also easy to use – and at
the same time, we have to accept the reality, which is that bugs and mistakes
happen. Nobody writes perfect code. There are two ways to deal with this: one is
to catch mistakes before they happen and prevent them entirely, and the other is
to catch mistakes more easily when they happen and help the user resolve them.
Type-based data validation
In spaCy v3, we finally dropped Python 2, so we were able to embrace some of the
newer Python features, like type hints! Type hints let you define the
expected types of variables. For instance, adding : int to a function
parameter lets you declare that the value should be an integer. Static type
checkers like mypy can then analyze your code and point out potential mistakes,
and modern editors can offer hints and auto-complete.
def add_numbers(a: int, b: int) -> int:
return a + b
Type hints have sparked a whole new ecosystem of developer tools, including
libraries that use them at runtime, for example, to validate data passing
through an application. One of those libraries is
Pydantic, which powers a lot of our
data validation in spaCy and Thinc. In fact, it’s a key component of spaCy’s
config system and helps us make sure that the config settings you pass in are
valid and complete – even those provided to custom registered functions!
We were first introduced to Pydantic by my former colleague
Sebastián and his library
FastAPI, which uses it extensively to
define data models for API requests and responses. The idea is pretty simple:
you declare a data model as a subclass of Pydantic’s
BaseModel and add type
hints to the fields. You can then instantiate the class with your data, and the
values will be converted to the specified types, if possible. If not, you’ll see
a validation error that points out the field, its value, and the expected type.
If you’ve worked with JSON schemas before, it’s basically the same idea, just
powered by type hints. In fact, you can also export JSON schemas based on
Pydantic models.
from typing import Optional
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: Optional[str] = None
price: float
tax: Optional[float] = None
app = FastAPI()
@app.post("/items/")
async def create item(item: Item):
return item
Pydantic lets you use basic standard library types like int or bool but it
also includes various custom types to validate different data types. For
example, types for file paths, URLs, or strict and constrained types, like a
strict string that only accepts actual strings and not any types that can be
coerced to a string, or positive_int, which only accepts positive integers.
So, what’s Pydantic used for in the config system? When you’re training a model,
spaCy will use the config to construct all required objects, and call the
registered functions with the arguments defined in their config blocks. Since
the config can also express nested structures, the result of one function may
also be passed into another, like a learning rate schedule that’s used by the
optimizer. If something is wrong and a setting is specified incorrectly or is
missing, we want to be able to exit early and tell you what the problem is so
you can fix it. This is done by validating the config blocks against
Pydantic data models.
For top-level properties in blocks, we can provide a base schema. We’ve also
configured it to explicitly forbid extra fields, so if you have a typo in a
name, you’ll see an error as well. The implementation here is pretty simple:
after we’ve parsed the config as a dictionary, we can call the schema on it and
handle the validation error – everything else is taken care of by Pydantic.

In addition to just regular settings, spaCy’s config also allows references to
registered functions using the @-syntax, and all other settings in the block are
passed into the function as arguments. Of course, we also want these functions
to be able to define the types they expect, and luckily, there’s already a
built-in mechanism for that: Python type hints for function parameters!
To validate a config block and create the Pydantic model, we can first inspect
the function arguments and their defaults and type hints, if available. This is
pretty easy using the built-in
inspect module. Next, we can
create a dynamic Pydantic model using this information. If a parameter doesn’t
specify a default value, we assume it’s required, and if there’s no type hint,
we assume it’s Any. We can then call the Pydantic model on the data provided
by the config block and check whether the settings are compatible function
arguments.

Because the config is resolved bottom-up, we already have a function’s return
value when we resolve and validate its parent block. For example, if we have a
function that returns a list and its return value is passed into another
function that expects a list, we can validate that and even catch problems where
a registered function is returning an unexpected value.
The dynamic Pydantic models we create for registered functions also let us
provide another useful task: auto-filling! If a function defines default
values, we’ll know about them and we can add them back into the config if
they’re not present. This is important to keep the config reproducible and avoid
hidden defaults. Your registered functions can still define default values – but
at any point, you’ll be able to auto-generate a complete config with all
settings that are going to be used. spaCy’s
init fill-config command takes a
partial config and outputs the validated and auto-filled version. It can even
show you a pretty visual diff so you can see which fields were added or deleted.

Under the hood, a big part of machine learning is computing things with
multi-dimensional arrays, and then passing them all the way through your network
and back. Even a small mistake, like a mismatch of input and output dimensions,
can cost you hours or even days of painful debugging. You only need one single
hyperparameter to be set incorrectly or inconsistently for your model to produce
confusing results or fall apart entirely. Debugging neural networks is probably
among the most significant obstacles for developer productivity, so it’s
something we really wanted to tackle. If we can prevent bugs before they happen,
and assist developers with debugging the remaining problems, they’ll be able to
spend more time focusing on the interesting stuff: building the actual
application.

spaCy’s machine learning library Thinc includes custom types
you can use in your code, including types for the most common arrays, like
Floats2d for a two-dimensional array of floats, or Ints1d for a
one-dimensional array of integers. Even before static analysis and other fancy
type checks, typing your code, especially the abstract parts, has the big
advantage of making it more readable. Just knowing what’s supposed to go in and
out can make it so much easier to understand a piece of code and share it with
others.
If you’re using a modern editor like Visual Studio Code and enable
Mypy linting, the static type checker flags the
returned variable if it’s not what the function expected. Thinc implements
several array transformation methods via the backend, available as model.ops.
This will either be NumPy or CuPy, depending on whether you’re on CPU or GPU. If
the static type checker detects a different number of dimensions, for example,
then it knows that something is likely wrong, whether it’s the transformation,
the expected input type or the declared expected output type, or any combination
of those things. You’ll be able to tell this before even running the code. At
runtime, a small bug like this could have easily led you down a rabbit hole of
“can’t broadcast shape” errors.

The cool thing about Mypy is that you can extend it with custom plugins for use
cases specific to your library. For Thinc, we implemented a plugin that performs
additional checks when you use a combinator like
chain that takes two or more layers
and composes them as a single feed-forward network. In this example, the first
layer outputs a Floats2d array but the next layer expects input of type
Ragged, a ragged array. Even without running the code, Mypy is able to flag
this mismatch that likely indicates a bug.
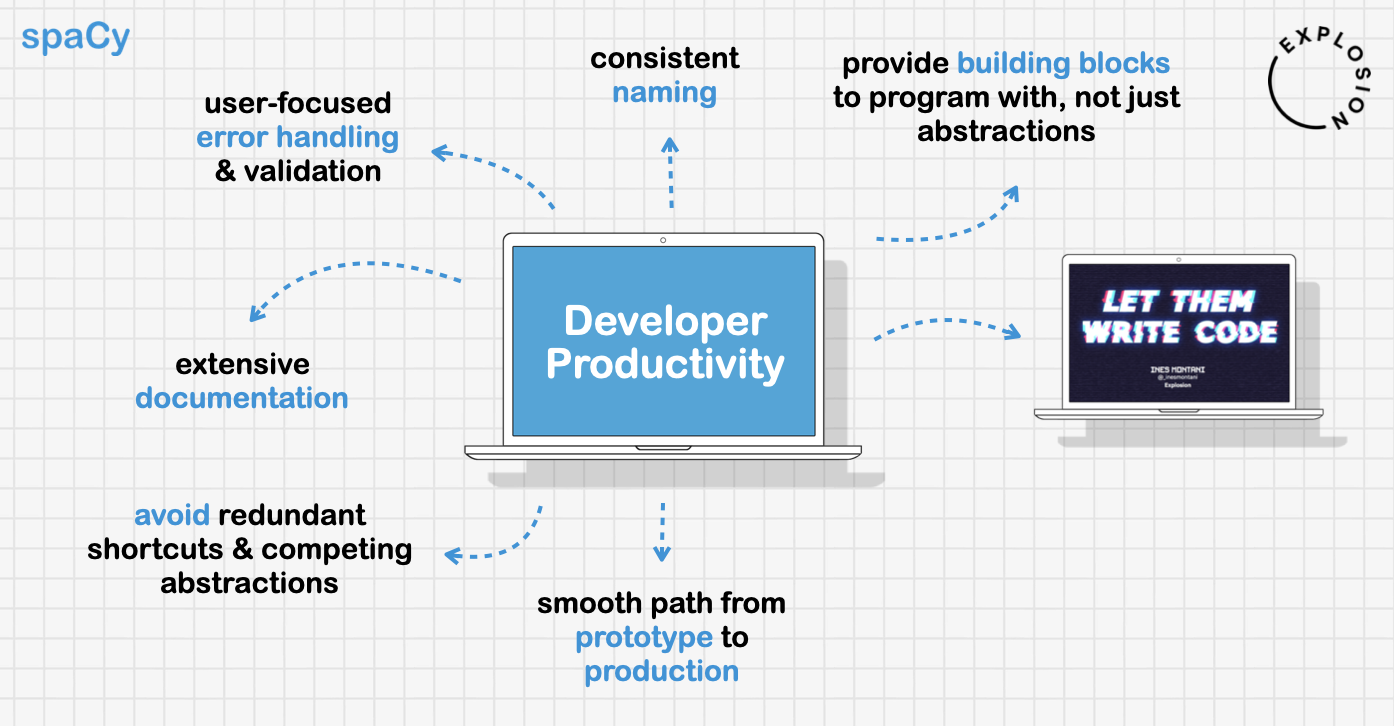
Software projects are made of choices — that’s really what any type of design is
about. While creating spaCy, the questions we kept coming back to when making
our decisions were all about developer productivity. This came up in lots of
little decisions and in some of the bigger architectural questions. We paid a
lot of attention to details like naming, error handling, and documentation. We
also thought carefully about what not to do, especially avoiding redundant
shortcuts and competing abstractions.
We’ve been especially careful to avoid API decisions that can force the user to
backtrack. We want to make sure that you don’t start solving a problem one way,
and then find you have to use an alternate API that’s faster or supports some
different combination of features. This is part of what we mean when we talk
about providing a “smooth path from prototype to production”. For most
projects, shipping to production is an ongoing process, not a one-time event. If
you’ll always be in development, it’s not ideal to have “development code” that
just needs to be torn down and rewritten at some point.
Embracing the complexity
Perhaps the most important thing we decided not to do is to hide away the
complexities of machine learning. Developers need to be able to program with the
library, which means putting the pieces together to build their own solutions.
This is why one of our mottos is “let them write code.” The alternative is a
library that tries to make everything just one function call. This ends up
feeling like a kitchen full of uni-tasker gadgets. You don’t want to be
rummaging through a drawer of egg slicers, papaya cubers, and halibut
tenderizers every day. It’s much better to have a smaller set of tools you know
and understand. You don’t solve any problems by just abstracting away the
complexities of machine learning – you need to embrace them, productively.