The importance of integrating artificial intelligence in finance stems from its ability to process vast amounts of data at unprecedented speeds, enabling financial institutions to make more informed decisions and improve operational efficiencies.
To understand what AI brings to the table, let’s first delve into the basics of AI as per recent trends. Let’s start with the basic use case the language models were designed to solve and predict the next word in a sequence based on probability learned from trained data. This training grew to a scale of processing billions of parameters using massive datasets. There comes the true potential realization of the models, allowing models to capture more complex relations in language.
Next comes the breakthrough, i.e., transformer architecture, which plays a pivotal role in LLM history as this process can consider all words simultaneously, weigh their importance differently for each task, and maintain multiple perspectives through multiple loads. The models were trained on vast amounts of unlabeled text data allowing them to have a broad understanding of the language.
Let’s imagine you are a financial analyst using an AI-powered algorithm. Let’s say you input the following statement: “Assess the credit risk for a tech startup seeking a $500,000 loan, considering their innovative product, recent market trends, and founder’s credit history.”
Let’s delve into what is happening behind the scenes.
Input Processing
The LLM tokenizes the input query, breaking it down into individual words and sub-words that it can process.
Words are first tokenized: [“Assess”, “the”, “credit”, “risk”, “for”, “a”, “tech”, “startup”, “seeking”, “a”, “$500,000”, “loan”, “considering”, “their”, “innovative”, “product”, “recent”, “market”, “trends”, “and”, “founder’s”, “credit”, “history”]
Sub-Tokenizing
Some words are further broken down into subwords,
- “startup” might become [“start”, “##up”]
- “$500,000” might be tokenized as [“$”, “500”, “##,”, “##000”]
Special token addition: [START] and [END] are added to the given tokens
Each token is converted to a unique numeric ID based on the model’s vocabulary.
If the model encounters unfamiliar words, it may use sub-word tokenization to represent them using known components.
Contextual Understanding
The context understanding step in an LLM involves identifying and extracting key elements from the input query. Let’s break down how the model identifies these key elements:
Loan amount: $500,000
The model recognizes the dollar sign “$” followed by a numeric value as the loan amount. It understands that this is a crucial piece of information for assessing credit risk, as the size of the loan impacts the level of risk involved.
Company type: Tech startup
The model identifies “tech startup” as a specific type of company. This is important because different industries and company stages have varying risk profiles. Tech startups, in particular, are often associated with high potential but also high risk.
Factors to Consider
- Innovative product
- Recent market trends
- Founder’s credit history
The underlying technical process in an LLM that enables this understanding of loan size and its impact on credit risk involves several key components:
1. Pre-Training on Vast Datasets
LLMs are pre-trained on massive textual data that include financial documents, news articles, academic papers, and other relevant sources. This pre-training allows the model to develop a broad understanding of financial concepts, including credit risk assessment principles.
2. Transformer Architecture
The transformer architecture, which is one of the biggest breakthroughs of modern LLMs, allows the model to process input tokens in parallel and establish complex relationships between different parts of the input.
3. Contextual Embeddings
Each token in the input is represented as a high-dimensional vector (embedding) that captures its meaning in the specific context. The embedding for “$500,000” would encode information about its magnitude and its relationship to credit risk concepts.
4. Fine-Tuning
If the model had been fine-tuned on financial or credit risk assessment tasks, it would have further refined its ability to make these specific connections.
The LLM uses vector embeddings to represent concepts and information in its knowledge base. Each piece of information about tech startup ecosystems, market trends, and credit risk factors is encoded as a high-dimensional vector. The most relevant information is retrieved based on the highest similarity scores. Retrieved information is scored based on its relevance to the specific context of assessing credit risk for a tech startup. When the query is processed, the LLM performs a semantic search within its knowledge base to make these steps possible.
LLM Architecture (Possible)
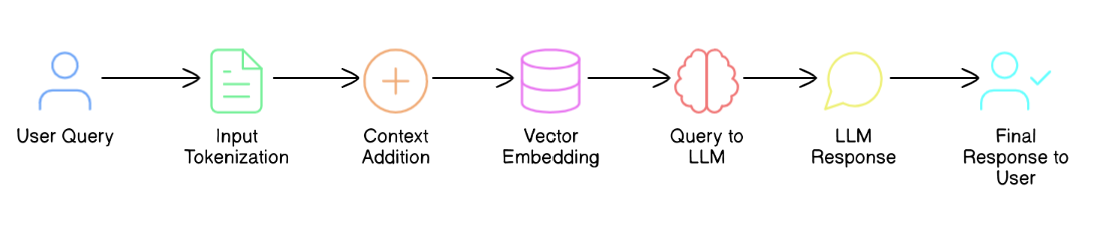
Imagine you’re a bank manager deciding whether to give a $500,000 loan to a tech startup. Instead of just relying on your memory or outdated information you have in previously issued loan data, you would refer to the most recent information and pull up the latest info on how tech startups are performing right now. It’s like having a real-time pulse on the industry. You would then grab the most recent financial data about the startup and its founder. Compare the startup product with existing products. Now, this manual process would take time, but providing the same information as a plug-in to AI is similar to RAG.
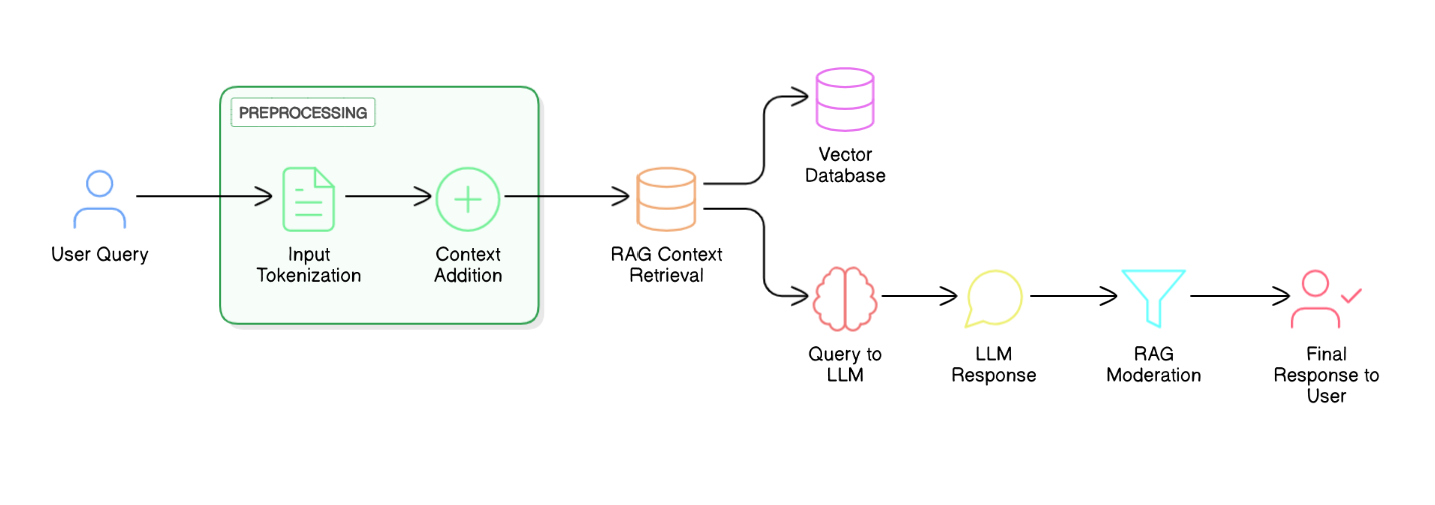
RAG is like having a super-smart assistant who can quickly grab the most up-to-date and relevant information for you. Retrieval-augmented generation (RAG) is emerging as a valuable technique for deploying LLMs safely and effectively. RAG implementation alongside LLM will provide a robust retrieval mechanism that provides relevant, verified data into the model’s responses, making it particularly useful in finance applications.
Alright, let me break down the RAG workflow for moderating context and response in a nutshell. First off, when a query comes in, the RAG system kicks into action by retrieving relevant information from its knowledge base — think of it as a super-smart librarian pulling out the right books. This retrieved info forms the context for the AI to work with.
Next, the system combines this context with the original query and feeds it into an LLM. The LLM then generates a response based on this enriched input. But here’s the clever bit: before spitting out the final answer, RAG applies a moderation layer. This layer checks the generated response against predefined rules and guidelines; it’s like having a strict English teacher reviewing your essay. If the response passes muster, it’s delivered to the user. If not, it’s either refined or flagged for human review.
This whole process ensures that the AI’s responses are not only relevant and accurate but also adhere to the financial institution’s policies and regulatory requirements. It’s like having a built-in fact-checker and compliance officer all rolled into one, making sure every output is top-notch and kosher!
Ok, let me wrap up with a take on the future of AI in finance, RAG is just the tip of the iceberg when it comes to AI in finance. It’s like we’ve just upgraded from a basic feature phone to a smartphone, there’s so much more to explore! Here’s what I reckon is coming down the pipeline:
- Advanced integration. We’ll see RAG combined with other AI technologies, creating more powerful tools for financial analysis and decision-making.
- Improved explainability. With increasing regulations, AI systems will need to be more transparent in their decision-making processes. This is the part that is currently called the black box of AI.
- Real-time adaptation. Future AI will update and adapt more quickly, responding to market changes almost instantly. This is currently unimaginable, especially in slow-moving finance technologies where you still see legacy COBOL kind of language running massive systems.
- Ethical AI focus. There will be a greater emphasis on developing AI systems that are fair and promote inclusive financial practices.
Conclusion
Financial institutions that adopt these evolving AI technologies will have a significant advantage in the market. The future of finance is closely tied to AI advancements, and RAG is just the first step in this exciting journey. It’s going to be quite interesting to see how these technologies shape the financial landscape in the coming years.