Hello Devs👋
If you’re trying to build anything that involves search, semantic understanding, retrieval-augmented generation (RAG), or recommendation systems, embedding models are best for these.
In this article, I’ll walk you through some powerful embedding models you can use in your next project which are free as well as open-source.
Let’s get started🚀
First, let’s understand:
🔍 What are Embedding Models?
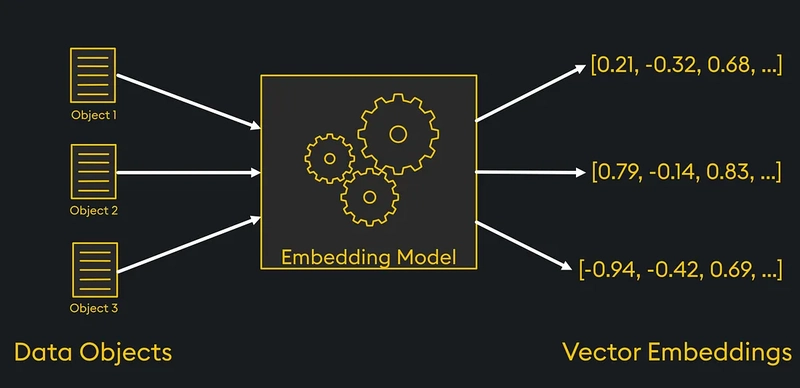
Embedding models are machine learning techniques that transform data (like text/code, images, or audio) into numerical representations, or vectors, that capture semantic relationships and allow for efficient comparison and analysis.
These models takes text/code/images as an input, convert them into dense numerical vectors (embeddings) that represent the semantic meaning. These vectors can then be used to:
Now, let’s check the models you can use to achieve the same.
📦 Popular Embedding Models (Free & Open-Source)
Qodo-Embed-1
Qodo-Embed-1 by Qodo is a state-of-the-art code embedding model designed for retrieval tasks. This model is optimized for natural language-to-code and code-to-code retrieval, making it highly effective for applications such as code search, retrieval-augmented generation (RAG), and contextual understanding of programming languages.
Recently, I tried this model and I’m impressed with the model’s accuracy and its semantic search capability.
You can check the detailed article here for the same.
This model is best for Code Search & Dev Tooling.
BGE Models
This model supports Multi-Functionality, Multi-Linguality, and Multi-Granularity.
-
Multi-Functionality: It can simultaneously perform the three common retrieval functionalities of embedding model: dense retrieval, multi-vector retrieval, and sparse retrieval. -
Multi-Linguality: It can support more than 100 working languages. -
Multi-Granularity: It is able to process inputs of different granularities, spanning from short sentences to long documents of up to 8192 tokens.
This model is best for: Search, semantic ranking, chatbots.
E5
This is unified model for query and passage encoding.
It is trained on diverse datasets like queries, wiki, QA pairs etc.
This model is best for: Text search, FAQ retrieval, document ranking.
MiniLM / MPNet
This model is extremely lightweight and fast for production-scale usage. It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
Best for: Real-time inference, low-latency applications.
Instructor-XL / Instructor-Base
Instructor-Base is an instruction-finetuned text embedding model that can generate text embeddings tailored to any task like classification, retrieval, clustering, text evaluation etc..
Best for: Multi-task embeddings and contextualized representation.
⚙️ Getting Started
All these models are available on HuggingFace and you can use them from sentence_transformers library.
pip install sentence_transformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Qodo/Qodo-Embed-1-1.5B", trust_remote_code=True)
sentences = [
"That is a happy person",
"That is a happy dog",
"That is a very happy person",
"Today is a sunny day"
]
embeddings = model.encode(sentences)
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [4, 4]
This is just an example snippet. You can pass the model name you want to use.
That’s It.🙏
Thank you for reading this far. If you find this article useful, please like and share this article. Someone could find it useful too.💖
Connect with me on X, GitHub, LinkedIn
