Introduction
In this blog, we share the journey of building a Serverless optimized Artifact Registry from the ground up. The main goals are to ensure container image distribution both scales seamlessly under unpredictable and bursty Serverless traffic and stays available under challenging scenarios such as major dependency failures.
Containers are the modern cloud-native deployment format which feature isolation, portability and rich tooling eco-system. Databricks internal services have been running as containers since 2017. We deployed a mature and feature rich open source project as the container registry. It worked well as the services were generally deployed at a controlled pace.
Fast forward to 2021, when Databricks started to launch Serverless DBSQL and ModelServing products, millions of VMs were expected to be provisioned each day, and each VM would pull 10+ images from the container registry. Unlike other internal services, Serverless image pull traffic is driven by customer usage and can reach a much higher upper bound.
Figure 1 is a 1-week production traffic load (e.g. customers launching new data warehouses or MLServing endpoints) that shows the Serverless Dataplane peak traffic is more than 100x compared to that of internal services.
Based on our stress tests, we concluded that the open source container registry could not meet the requirements of Serverless.
Serverless challenges
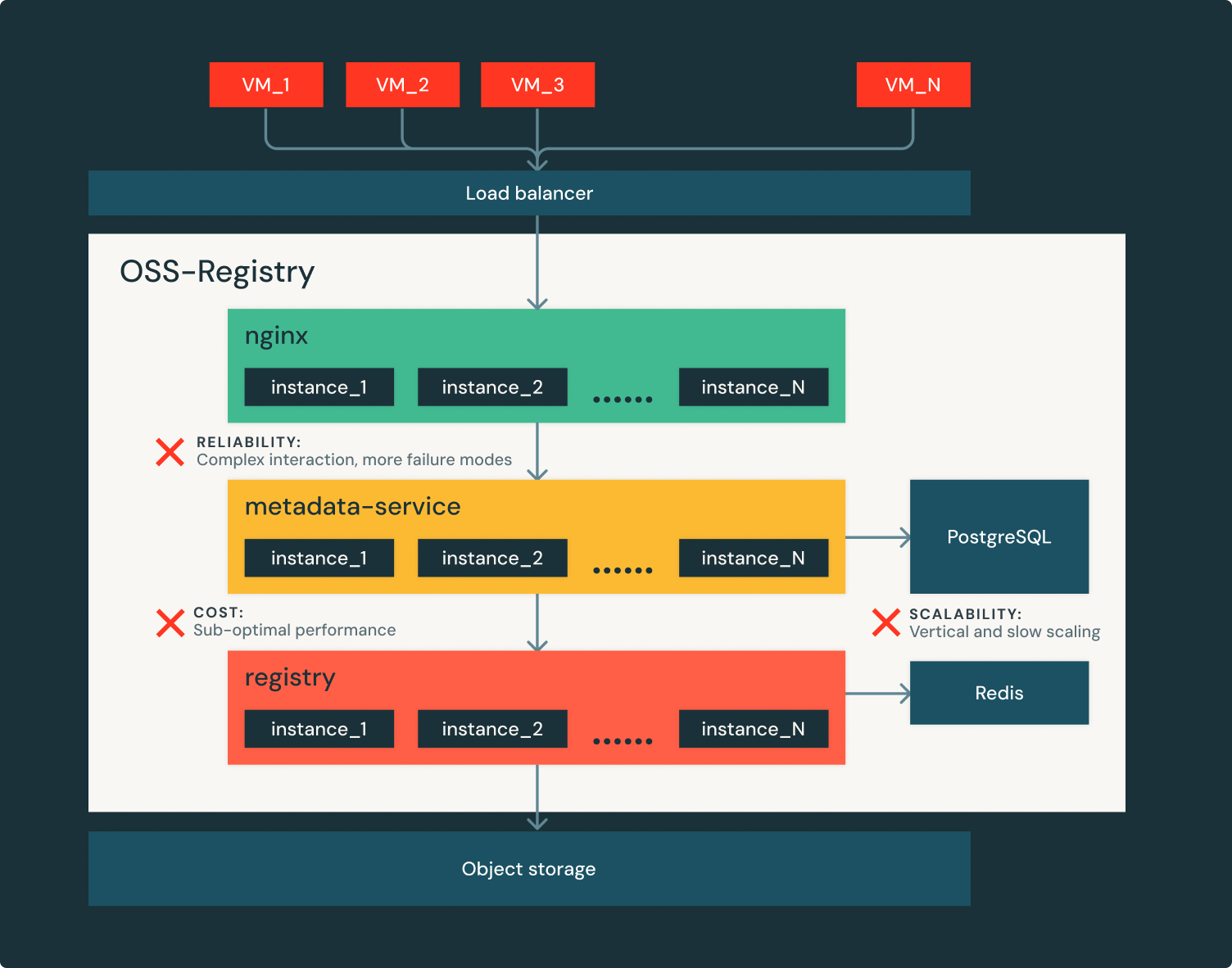
Figure 2 shows the main challenges of serving Serverless workloads with open source container registry:
- Hard to keep up with Databricks’ growth:
- Container image metadata is backed by relational databases, which scale vertically and slowly.
- At peak traffic, thousands of registry instances need to be provisioned in a few seconds, which often become a bottleneck on the critical path of image pulling.
- Not sufficiently reliable:
- Requests serving is complex in the OSS based architecture, which introduces more failure modes.
- Dependencies such as relational database or cloud object storage being down leads to a regional total outage.
- Costly to operate: The OSS registries are not performance optimized and tend to have high resource usage (CPU intensive). Running them at Databricks’ scale is prohibitively expensive.
What about cloud managed container registries? They are generally more scalable and offer availability SLA. However, different cloud provider services have different quotas, limitations, reliability, scalability and performance characteristics. Databricks operates in multiple clouds, we found the heterogeneity of clouds did not meet the requirements and was too costly to operate.
Peer-to-peer (P2P) image distribution is another common approach to improve scalability, at a different infrastructure layer. It mainly reduces the load to registry metadata but still subject to aforementioned reliability risks. We later also introduced the P2P layer to reduce the cloud storage egress throughput. At Databricks, we believe that each layer needs to be optimized to deliver reliability for the entire stack.
Introducing the Artifact Registry
We concluded that it was necessary to build Serverless optimized registry to meet the requirements and ensure we stay ahead of Databricks’ rapid growth. We therefore built Artifact Registry – a homegrown multi-cloud container registry service. Artifact Registry is designed with the following principles:
- Everything scales horizontally:
- Removed relational database (PostgreSQL); instead, the metadata was persisted into cloud object storage (an existing dependency for images manifest and layers storage). Cloud object storages are much more scalable and have been well abstracted across clouds.
- Removed cache instance (Redis) and replaced it with a simple in-memory cache.
- Scaling up/down in seconds: added extensive caching for image manifests and blob requests to reduce hitting the slow code path (registry). As a result, only a few instances (provisioned in a few seconds) need to be added instead of hundreds.
- Simple is reliable: consolidated 3 open source micro-services (nginx, metadata service and registry) into a single service, artifact-registry. This reduces 2 extra networking hops and improves performance/reliability.
As shown in Figure 3, we essentially transformed the original system consisting of 5 services to a simple web service: a bunch of stateless instances behind a load balancer serving requests!
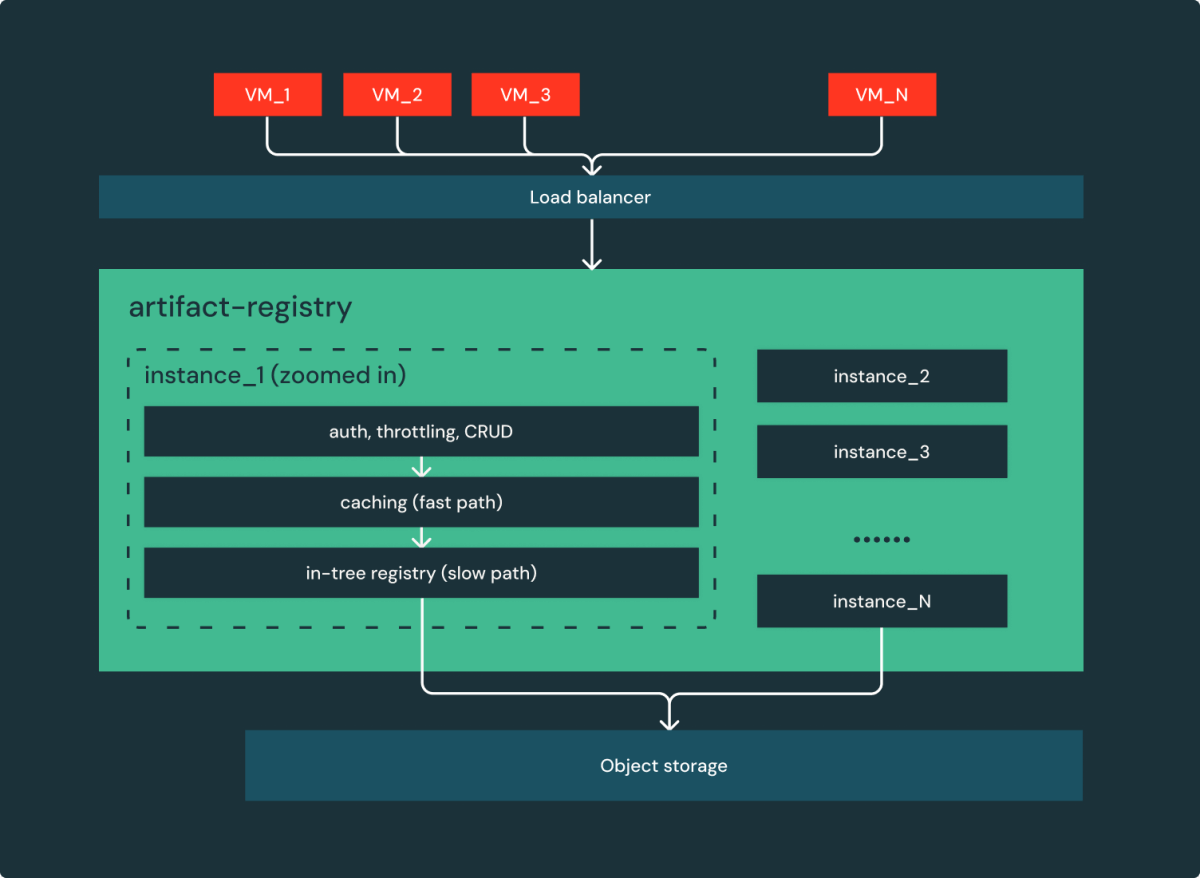
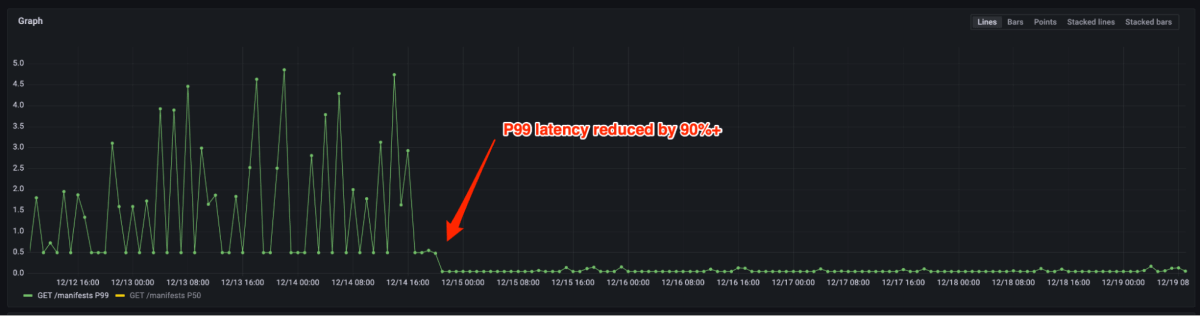
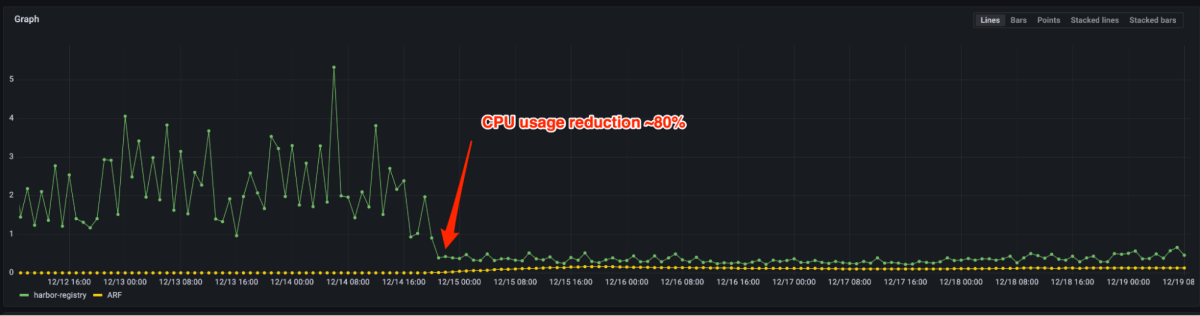
Figure 4 and 5 show that P99 latency reduced by 90%+ and CPU usage reduced by 80% after migrating from the open source registry to Artifact Registry. Now we only need to provision a few instances for the same load vs. thousands previously. In fact, handling production peak traffic does not require scale out in most cases. In case auto-scaling is triggered, it can be done in a few seconds.
The main design decision is to completely replace relational databases with cloud object storage for image metadata. Relational databases are ideal for consistency and enriched query capability, but have limitations on scalability and reliability. For example, every image pull request required authentication/authorization, which was served by PostgreSQL in the open source implementation. The traffic spikes regularly caused performance hiccups. The lookup query used by auth can be easily replaced with a GET operation of a more scalable Key/Value storage. We also made careful tradeoffs between convenience and reliability. For instance, using a relational database, it is easy to aggregate the image count, total size grouping by different dimensions. Supporting such features, however, is non-trivial in object storage. In favor of reliability and scalability, we decided Artifact Registry to not support such stats.
Surviving cloud object storages outage
With service reliability significantly improved after eliminating the dependencies of relational database, remote caching and internal microservices, there is still a failure mode that occasionally happens: cloud object storage outages. Cloud object storages are generally very reliable and scalable; however, when they are unavailable (sometimes for hours), it potentially causes regional outages. Databricks’ holds a high bar on reliability to minimize impact of underlying cloud outages and continue to serve our customers.
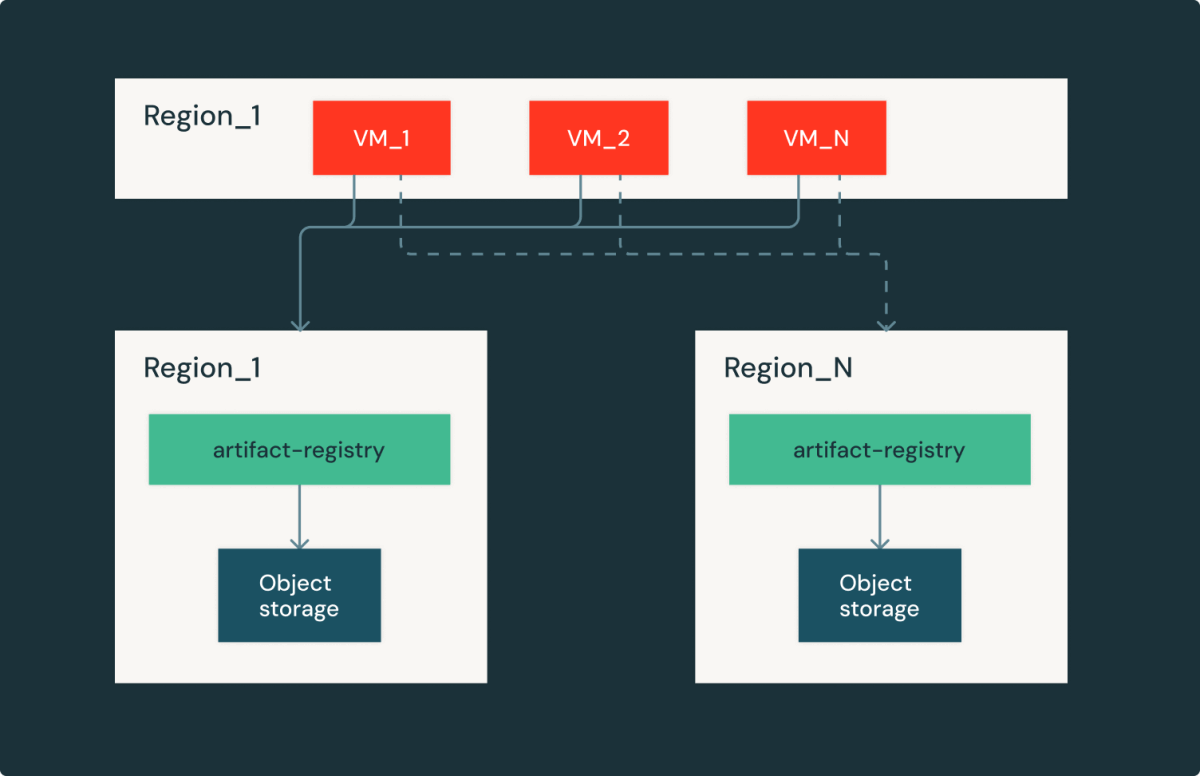
Artifact Registry is a regional service, which means each cloud/region has an identical replica within the region. This setup gives us the ability to fail over to different regions with the tradeoff on image download latency and egress cost. By carefully curating latency and capacity, we were able to quickly recover from cloud provider outages and continue serving Databricks’ customers.
Conclusions
In this blog post, we shared our journey of building Databricks container registry from serving low churn internal traffic to customer facing bursty Serverless workloads. We purpose-built Serverless optimized Artifact Registry. Compared to the open source registry, it delivered 90% P99 latency reduction and 80% resource usages. In addition, we designed the system to tolerate regional cloud provider outages, further improving reliability. Today, Artifact Registry continues to be a solid foundation that makes reliability, scalability and efficiency seamless amid Databricks’ rapid Serverless growth.
Acknowledgement
Building reliable and scalable Serverless infrastructure is a team effort from our major contributors: Robert Landlord, Tian Ouyang, Jin Dong, and Siddharth Gupta. The blog is also a team work – we appreciate the insightful reviewers provided by Xinyang Ge and Rohit Jnagal.