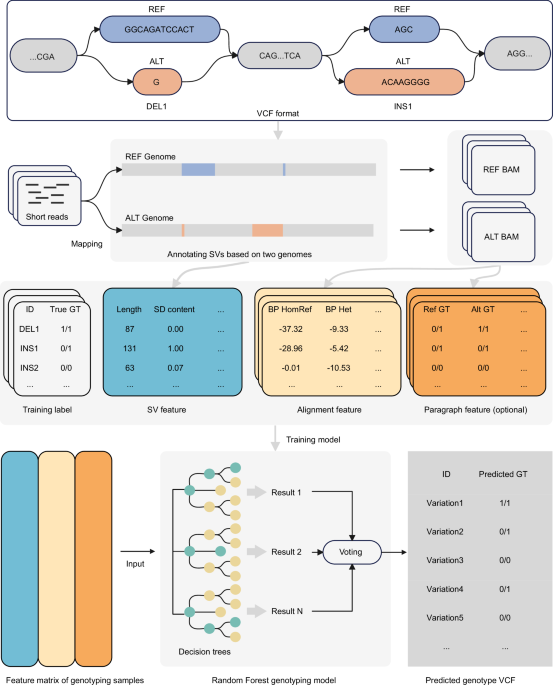
March 11, 2025

Self-Organising Textures
Contents This article is part of the Differentiable Self-organizing Systems Thread, an experimental format collecting invited short articles delving into differentiable self-organizing systems, interspersed with critical commentary from several experts in adjacent fields. Self-classifying MNIST Digits Adversarial Reprogramming of Neural Cellular Automata Neural Cellular Automata (NCA We use NCA to refer to both Neural Cellular Automata and Neural Cellular Automaton.) are capable of learning a diverse set of behaviours: from generating stable, regenerating, static images , to segmenting images , to learning to “self-classify” shapes . The inductive bias imposed by using cellular automata is powerful. A system of individual