With rapid progress in the fields of machine learning (ML) and artificial intelligence (AI), it is important to deploy the AI/ML model efficiently in production environments.
This blog post discusses an end-to-end ML pipeline on AWS SageMaker that leverages serverless computing, event-trigger-based data processing, and external API integrations. The architecture downstream ensures scalability, cost efficiency, and real-time access to applications.
In this blog, we will walk through the architecture, explain design decisions, and examine the key AWS services used to build this system.
Architecture Overview
The AWS-based ML pipeline consists of multiple components that communicate with one another seamlessly to perform model execution, data storage, processing, and API exposure. The workflow includes:
- ML Model Execution in AWS SageMaker
- Storing data in AWS S3, DynamoDB, and Snowflake
- Event-based processing using AWS Lambda and AWS Glue
- Real-time API integration with AWS Lambda and Application Load Balancer
- Routing traffic to applications through AWS Route 53
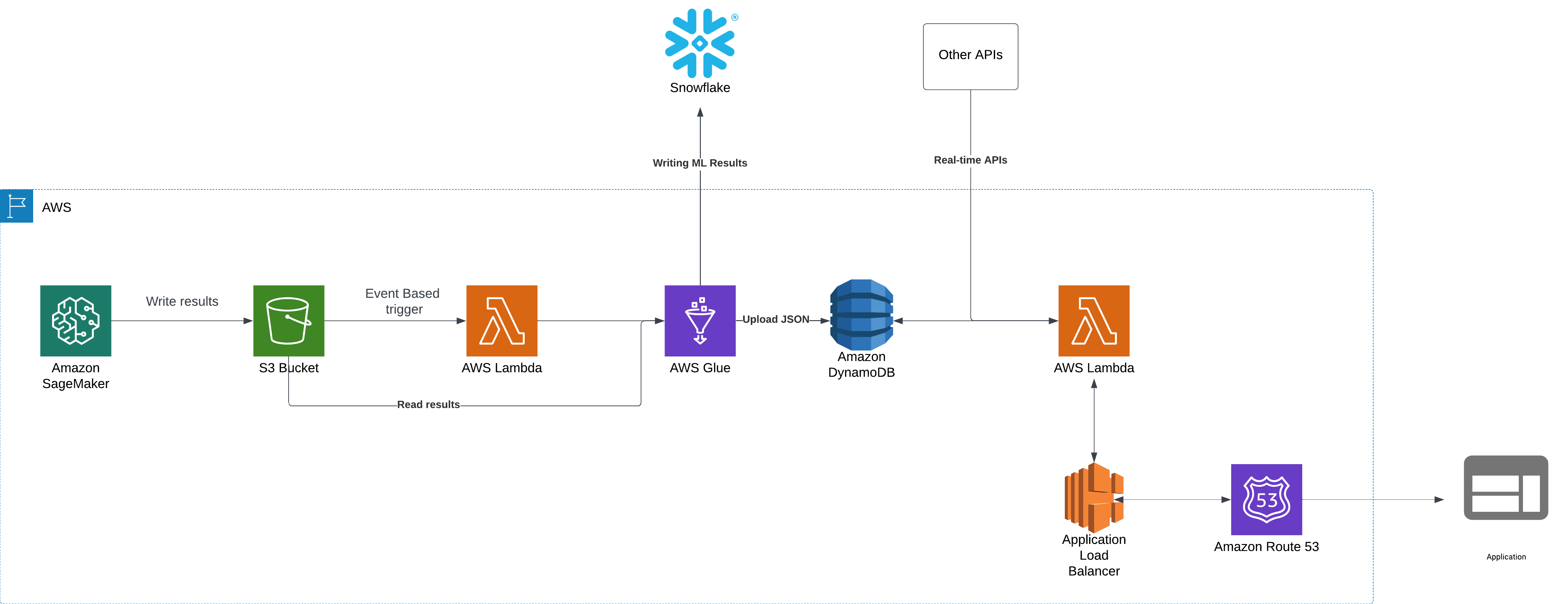
Step 1: Running of the ML Model on AWS SageMaker
The main component of the system is the ML model that runs on AWS SageMaker periodically to generate predictions. This is also called batch processing.
The SageMaker pipeline:
- Uses preprocessed data and results from previous runs.
- Applies the ML algorithms for inference.
- Writes the output in both JSON and Delta formats to an S3 bucket.
Why save data in JSON and Delta formats?
- JSON is lightweight and can be easily consumed by AWS DynamoDB for real-time querying.
- Delta format allows for efficient data loading into Snowflake for analytics and reporting.
Step 2: Event-Based Data Processing and Storage
Once SageMaker writes the output to an S3 bucket, an event-based trigger will automatically run the next steps.
- S3 Event Notification invokes an AWS Lambda function, as soon as the new “done” file is created in the corresponding S3 location, where the trigger was setup.
- The Lambda function invokes the AWS Glue job that:
- Processes and loads the JSON data from the S3 location into DynamoDB.
- Copies Delta data to Snowflake.
Why use AWS Glue for data ingestion?
- AWS Lambda has a max timeout of 15 minutes.
- Processing and uploading huge amounts of data might take more than 15 minutes.
- Glue ETL transformations ensure that structured and clean data ingestion is assured.
Step 3: API Processing and Real-Time Access
Now, the data stored in DynamoDB needs to be accessed by external applications. That’s done using APIs. We can use an AWS Lambda function to host the API code.
- API Lambda function is invoked when the application makes a request.
- The API Lambda function:
- Queries DynamoDB with the latest ML model results.
- Integrates with real-time APIs (third-party services) to enhance the results.
- Processes all this information and generates an API response.
Step 4: API Exposure Using Application Load Balancer (ALB)
To handle API traffic, the Lambda function is connected to an AWS Application Load Balancer (ALB).
Why use an Application Load Balancer?
- ALB routes traffic to the relevant Lambda function.
- Autoscales based on the number of API requests, ensuring high availability.
- Distributes traffic efficiently across multiple Lambda instances.
- Secures the API endpoints by performing authentication and request filtering.
Step 5: Routing API Calls Using Route 53
We integrate AWS Route 53 with the ALB to obtain a consistent API endpoint.
- Route 53 handles domain name resolution, making sure that the applications can easily connect to the API.
- It also supports custom domain mapping, allowing other teams to use a user-friendly API URL instead of directly accessing ALB endpoints.
- If the API Lambda is deployed in multiple regions, Route 53 can be configured to route traffic efficiently, ensuring reliability and failover even during high-traffic periods.
Most Critical Features of This Architecture
- Scalability – AWS services like SageMaker, Lambda, Glue, and DynamoDB handle loads dynamically
- Cost optimization – Use of on-demand DynamoDB, serverless Lambda, and event-based processing ensures efficient utilization of resources
- Real-time processing – Provides real-time access to the ML output with low-latency APIs
- Seamless integration – Supports integration with other real-time APIs, thereby enhancing results
- Cross-team collaboration – Exporting data to Snowflake helps businesses and other teams to run analytics against ML predictions
Future Enhancements and Considerations
- Streaming processing – Replacing batch flows with Kafka or Kinesis for real-time data processing.
- Automated model retraining – Use SageMaker Pipelines for automated model retraining.
Conclusion
This AWS-based ML architecture provides a scalable, automated, and efficient pipeline for running ML models, generating predictions, and serving real-time API responses. By utilizing AWS services such as SageMaker, Lambda, Glue, DynamoDB, ALB, and Route 53, the system ensures cost efficiency, high performance, and real-time data availability for downstream applications.
Would love to hear your thoughts!