Version 2.2 of the spaCy Natural Language Processing library is leaner, cleaner
and even more user-friendly. In addition to new model packages and features for
training, evaluation and serialization, we’ve made lots of bug fixes, improved
debugging and error handling, and greatly reduced the size of the library on
disk.
While we’re grateful to the whole spaCy community for their patches and support,
Explosion has been lucky to welcome two new team members who deserve
special credit for the recent rapid improvements: Sofie Van Landeghem and
Adriane Boyd have been working on spaCy full-time. This brings the core team
up to four developers – so you can look forward to a lot more to come.
spaCy v2.2 comes with
retrained statistical models, that include bug fixes and improved performance
over lower-cased texts. Like other statistical models, spaCy’s models can be
sensitive to differences between the training data and the data you’re working
with. One type of difference we’ve had a lot of trouble with is casing and
formality: most of the training data we have is text that is fairly well edited,
which has meant lower accuracy on texts which have inconsistent casing and
punctuation.
To address this, we’ve begun developing a new data augmentation system. The
first feature we’ve introduced in the v2.2 models is a word replacement system
that also supports paired punctuation marks, such as quote characters. During
training, replacement dictionaries can be provided, with replacements made in a
random subset of sentences each epoch. Here’s an example of the type of problem
this change can help with. The German NER model is trained on a treebank that
uses “ as its open-quote symbol. When Wolfgang Seeker
developed spaCy’s German support, he used a preprocessing
script that replaced some of those quotes with unicode or ASCII quotation marks.
However, one-off preprocessing steps like that are easy to lose track of –
eventually leading to a bug in the v2.1 German model. It’s much better to make
those replacements during training, which is just what the new system allows you
to do.
If you’re using the spacy train command, the
new data augmentation strategy can be enabled with the new
--orth-variant-level parameter. We’ve set it to 0.3 by default, which means
that 30% of the occurrences of some tokens are subject to replacement during
training. Additionally, if an input is randomly selected for orthographic
replacement, it has a 50% chance of also being forced to lower-case. We’re still
experimenting with this policy, but we’re hoping it leads to models that are
more robust to case variation. Let us know how you find it! More APIs for data
augmentation will be developed in future, especially as we get more evaluation
metrics for these strategies into place.
We’re also pleased to introduce pretrained models for two additional
languages: Norwegian Norwegian] and
Lithuanian. Accuracy on both of these languages
should improve in subsequent releases, as the current models make use of neither
pretrained word vectors nor the spacy pretrain command. The addition of these
languages has been made possible by the awesome work of the spaCy community,
especially TokenMill for the Lithuanian model, and
the
University of Oslo Language Technology Group
for Norwegian. We’ve been adopting a cautious approach to adding new language
models, as we want to make sure that once a model is added, we can continue to
support it in each subsequent version of spaCy. That means we have to be able to
train all of the language models ourselves, because subsequent versions of spaCy
won’t necessarily be compatible with the previous suite of models. With steady
improvements to our automation systems and new team members joining
spaCy, we look forward to adding more languages soon.
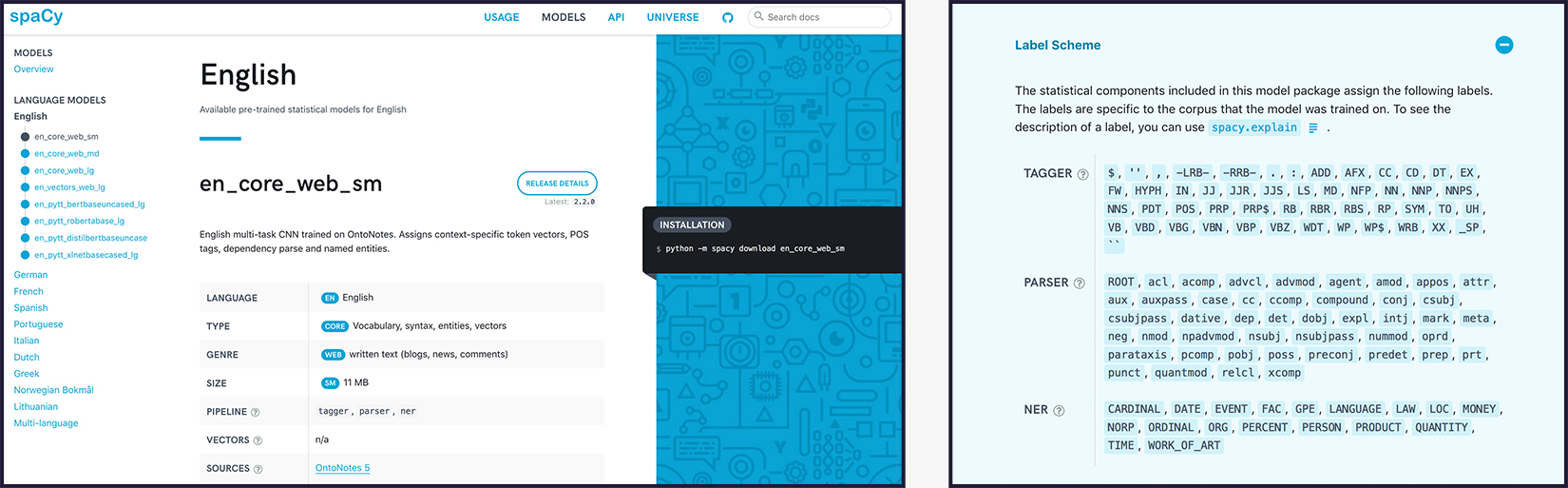
Better Dutch NER with 20 categories
Our friends at NLP Town have been making some great
contributions to spaCy’s Dutch support. For v2.2, they’ve gone even further, and
annotated a new dataset that should make the pretrained Dutch
NER model much more useful. The
new dataset provides OntoNotes 5 annotations over the
LaSSy corpus.
This allows us to replace the semi-automatic Wikipedia NER model with one
trained on gold-standard entities of 20 categories. You can see the updated
results in our new and improved models directory,
that now shows more detail about the different models, including the label
scheme. At first glance the new model might look worse, if you only look at the
evaluation figures. However, the previous evaluation was conducted on the
semi-automatically created Wikipedia data, which makes it much easier for the
model to achieve high scores. The accuracy of the model should improve further
when we add pretrained word vectors and when we wire in support for the
spacy pretrain command into our model
training pipeline.
spaCy v2.2 includes several usability improvements to the training and data
development workflow, especially for text categorization. We’ve improved error
messages, updated the documentation, and made the evaluation metrics more
detailed – for example, the evaluation now provides per-entity-type and
per-text-category accuracy statistics by default.
One of the most useful improvements is integrated support for the text
categorizer in the
spacy train command line interface. You can
now write commands like the following, just as you would when training the
parser, entity recognizer or tagger:
python -m spacy train en /output /train /dev --pipeline textcat
--textcat-arch simple_cnn --textcat-multilabel
You can read more about the data format required
in the API docs. To make training
even easier, we’ve also introduced a new
debug-data command, to validate your
training and development data, get useful stats, and find problems like
invalid entity annotations, cyclic dependencies, low data labels and more.
Checking your data before training should be a huge time-saver, as it’s never
fun to hit an error after hours of training.

As spaCy has supported
more languages, the disk footprint
has crept steadily upwards, especially when support was added for lookup-based
lemmatization tables. These tables were stored as Python files, and in some
cases became quite large. We’ve switched these lookup tables over to gzipped
JSON and moved them out to a separate package,
spacy-lookups-data, that
can be installed alongside spaCy if needed. Depending on your system, your spaCy
installation should now be 5-10× smaller.
pip install -U spacy[lookups]
Under the hood, large language resources are now powered by a consistent
Lookups API that you can also take advantage
of when writing custom components. Custom components often need lookup tables
that are available to the Doc, Token or Span objects. The natural place
for this is in the shared Vocab – that’s exactly the sort of thing the Vocab
object is for. Now custom components can place data there too, using the new
lookups API.
Efficient serialization is very important for large-scale text processing. For
many use cases, a good approach is to serialize a spaCy Doc object as a numpy
array, using the Doc.to_array method.
This lets you select the subset of attributes you care about, making
serialization very quick. However, this approach does lose some information.
Notably, all of the strings are represented as 64-bit hash values, so you’ll
need to make sure that the strings are available in your other process when you
go to deserialize the Doc.
The new DocBin class helps you
efficiently serialize and deserialize a collection of Doc objects, taking
care of lots of details for you automatically. The class should be especially
helpful if you’re working with a multiprocessing library like
Dask. Here’s a basic usage example:
import spacy
from spacy.tokens import DocBin
doc_bin = DocBin(attrs=["LEMMA", "ENT_IOB", "ENT_TYPE"], store_user_data=True)
texts = ["Some text", "Lots of texts...", "..."]
nlp = spacy.load("en_core_web_sm")
for doc in nlp.pipe(texts):
doc_bin.add(doc)
bytes_data = docbin.to_bytes()
nlp = spacy.blank("en")
doc_bin = DocBin().from_bytes(bytes_data)
docs = list(doc_bin.get_docs(nlp.vocab))
Internally, the DocBin converts each Doc object to a numpy array, and
maintains the set of strings needed for all of the Doc objects it’s managing.
This means the storage will be more efficient per document the more documents
you add – because you get to share the strings more efficiently. The
serialization format itself is gzipped msgpack, which should make it easy to
extend the format in future without breaking backwards compatibility.
spaCy’s PhraseMatcher class gives you an efficient way to perform
exact-match search
with a potentially huge number of queries. It was designed for use cases
like finding all mentions of entities in Wikipedia, or all drug or protein names
from a large terminology list. The algorithm the PhraseMatcher used was a bit
quirky: it exploited the fact that spaCy’s Token objects point to Lexeme
structs that are shared across all instances. Words were marked as possibly
beginning, within, or ending at least one query, and then the Matcher object was
used to search over these abstract tags, with a final step filtering out the
potential mismatches.
The key benefit of the previous PhraseMatcher algorithm is how well it scales
to large query sets. However, it wasn’t necessarily that fast when fewer queries
were used – making its performance characteristics a bit unintuitive –
especially since the algorithm is non-standard, and relies on spaCy
implementation details. Finally, its reliance on these details has introduced a
number of maintainence problems as the library has evolved, leading to some
subtle bugs that caused some queries to fail to match. To fix these problems,
v2.2 replaces the PhraseMatcher with a more straight-forward trie-based
algorithm. Because the search is performed over tokens instead of
characters, matching is very fast – even before the implementation was
optimized using Cython data structures. Here’s a quick benchmark searching over
10,000 Wikipedia articles.
| # queries | # matches | v2.1.8 (seconds) | v2.2.0 (seconds) |
|---|---|---|---|
| 10 | 0 | 0.439 | 0.027 |
| 100 | 795 | 0.457 | 0.028 |
| 1,000 | 11,376 | 0.512 | 0.043 |
| 10,000 | 105,688 | 0.632 | 0.114 |
When few queries are used, the new implementation is almost 20× faster
– and it’s still almost 5× faster when 10,000 queries are used. The
runtime of the new implementation roughly doubles for every order of magnitude
increase in the number of queries, suggesting that the runtimes will be about
even at around 1 million queries. However, the previous algorithm’s runtime was
mostly sensitive to the number of matches (both full and partial), rather than
the number of query phrases – so it really depends on how many matches are being
found. You might have some query sets that produce a high volume of partial
matches, due to queries that begin with common words such as “the”. The new
implementation should perform much more consistently, and we expect it to be
faster in almost every situation. If you do have a use-case where the previous
implementation was performing better, please let us know.
In case you missed it, you might also be interested in the new beginner-oriented
video tutorial series
we’re producing, in collaboration with data science instructor
Vincent Warmerdam. Vincent is building a a
system to automatically detect programming languages in large volumes of text.
You can follow his process from the first idea to a prototype all the way to
data collection and training a statistical named entity recogntion model
from scratch.
We’re excited about this series because we’re trying to avoid a common problem
with tutorials. Most tutorials only ever show you the “happy path”, of
everything working out exactly as the authors intended it. The problem’s much
bigger and more fundamental than technology: there’s a reason that
“draw the rest of the owl” meme
resonates so widely. The
best way to avoid this problem is to turn the pencil over to someone else, so
you can really see the process. Two episodes have already been released, and
there’s a lot more to come!